谷歌Gemini对4月中国国产开源模型的评价!4月国产开源模型谁最能打
2026年4月,中国大模型领域确实进入了“周更”甚至“日更”的疯狂节奏。如果你正在这几款模型之间纠结,最直接的结论是:已经没有所谓的“全能冠军”,只有特定场景下的“卷王”。
根据最新的社区实测反馈和各家发布的技术细节,这里有一份新鲜出炉的“避坑与入坑指南”:
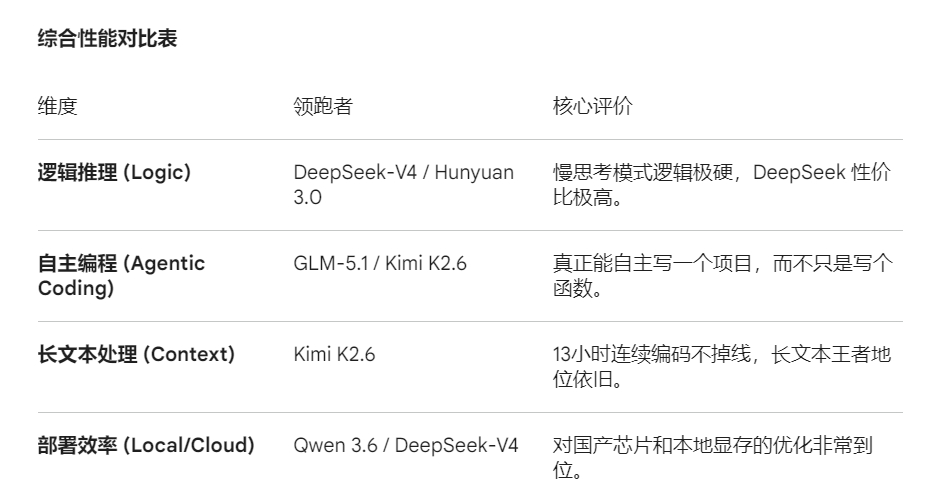
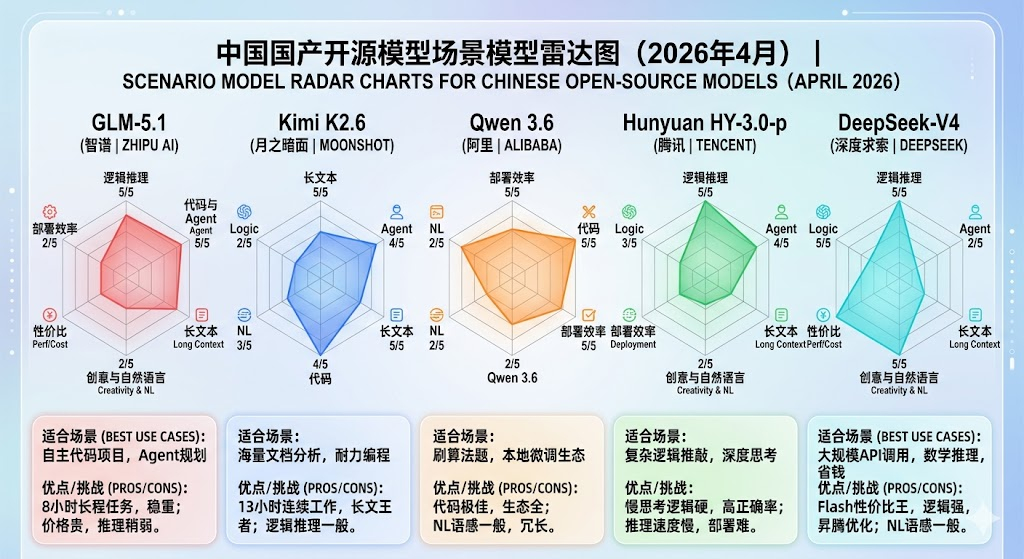
1. 智谱 GLM-5.1:工程级的“长效打工人”GLM-5.1 在 4 月 8 日发布后,最让人惊喜的不是它的 Benchmark 分数,而是它提出的 “8小时长程任务(Long Horizon Task)” 能力。
实际体验: 它不再只是和你对话,而是能像个初级实习生一样,在后台自主规划、运行并修改代码。如果你需要模型独立完成一个中型项目的 Bug 修复或从零搭建仓库,它的表现是目前开源界最稳的。
代价: 它的价格涨了 10%,目前是国产模型中唯一敢在价格上对齐 Claude 4.6 的,走的是高端路线。
2. DeepSeek-V4:极致的“性价比推理之神”DeepSeek 依然是那个搅动市场的“价格屠夫”,但 V4 这次在架构上玩了新花样(混合压缩注意力机制 CSA/HCA)。
实际体验: Flash 版本 的性价比高到离谱(1.25元/百万Tokens),且在数学推理和逻辑规划上几乎碾压了同级别的对手。如果你是个人开发者,或者需要大规模调用推理接口,DeepSeek-V4 是首选。
亮点: 它针对国产昇腾 950 芯片做了深度优化,在国产算力环境下的响应速度快得惊人。
3. 月之暗面 Kimi K2.6:长文本与代码的“耐力赛选手”Kimi 2.6 在 4 月 20 日更新后,继续死磕“长”和“准”。
实际体验: 它的长程编码能力提升到了 13小时连续工作。相比 GLM-5.1,Kimi 在处理超长上下文(尤其是阅读海量技术文档后再写代码)时的记忆保留度和逻辑一致性更有优势。
适合场景: 深度研报分析、超长项目重构。
4. 阿里 Qwen 3.6 与 腾讯混元 HY-3.0-previewQwen 3.6: 性能跨越很大,但目前的社区反馈呈现两极分化。在纯代码和数学场景表现极佳,但在自然语言的“语感”上略显臃肿(容易出现翻译腔或冗长废话)。
Hunyuan HY-3.0-preview: 引入了“快慢思考”融合机制(类似 o1 架构)。在处理需要反复推敲的复杂逻辑难题时,它能通过增加推理步数给出更准确的答案,不再是“快嘴”而是“脑补帝”。
💡 怎么选?如果你要写一整个复杂的软件工程:首选 GLM-5.1 或 Kimi K2.6。
如果你要刷算法题、做数学推导或省钱:闭眼入 DeepSeek-V4 (Flash)。
如果你要处理法律、金融等专业领域的海量文档:Kimi K2.6 的稳定性依然是第一梯队。
如果你追求极客感和本地化微调:Qwen 3.6 的开源社区生态目前依然是最活跃的。