DeepSeek开源DSpark框架:大模型推理速度飙升85%,AI聊天不再“转圈圈”!
今天看到个重磅消息,DeepSeek联合北京大学开源了DSpark推理加速框架,直接把大模型生成速度提升了60%-85%!更关键的是,代码、模型全开源了,开发者能直接用。
✨DSpark到底牛在哪?
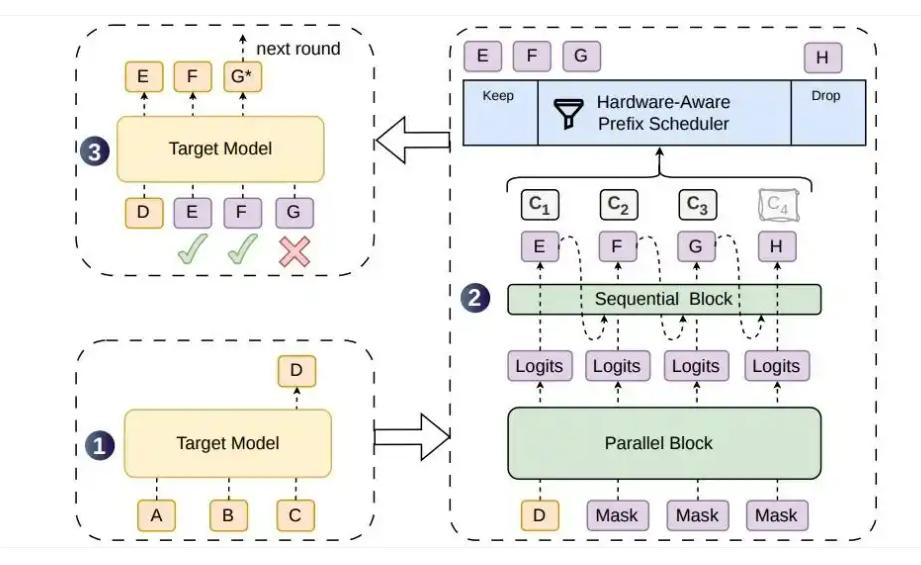
双架构融合:用并行主干网络一次性产出候选token,再加轻量级顺序模块注入前缀依赖,既保留并行架构的首位高接受率,又解决后续位置接受率衰减问题。
动态调度机制:模型会输出每个候选token的置信度分数,调度器根据并发请求量动态分配验证长度,优先把计算资源给存活概率高的token,避免资源浪费。
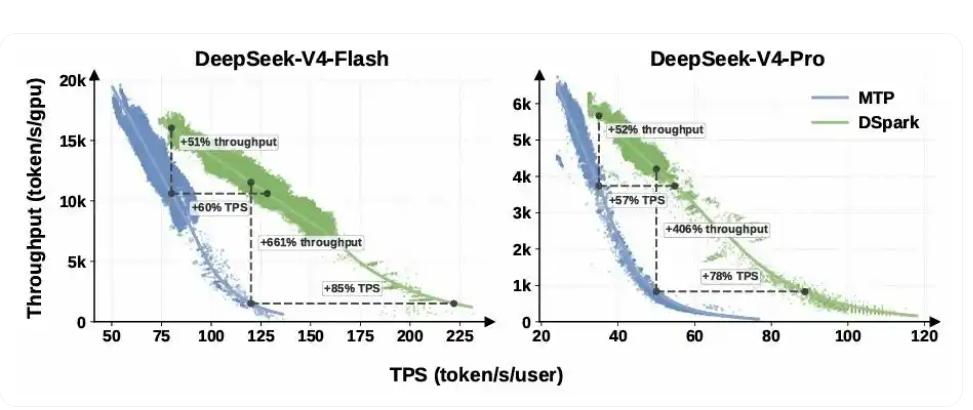
生产环境实测:在DeepSeek-V4-Flash引擎上,保证单用户80token/s时,吞吐量提升51%;SLA收紧到120token/s时,吞吐量优势达661%。
⚠️技术突破背后的价值:
解决核心痛点:大模型自回归生成方式导致推理延迟随输出长度线性增长,DSpark通过推测解码技术,用轻量级小模型生成候选token,大模型批量验证,无损质量前提下提升速度。
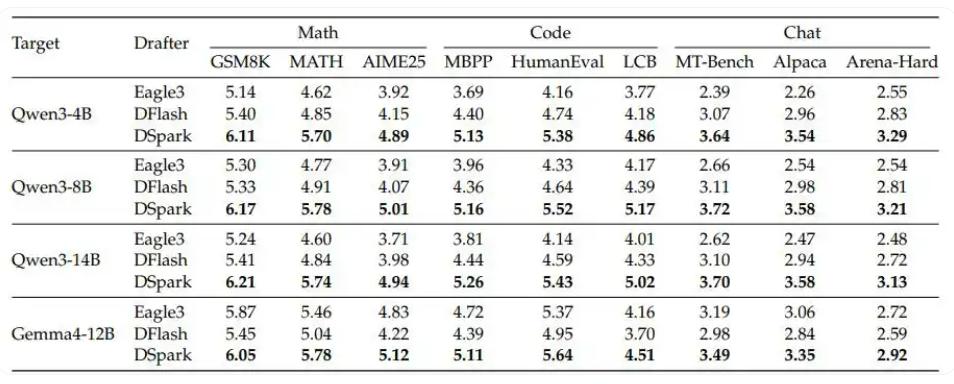
开源意义重大:DeepSpec项目已开源DSpark、DFlash、Eagle3三种草稿模型的训练代码和评估脚本,降低开发者门槛,推动推理加速技术普及。
工程优化细节:并行训练时仅传递隐藏状态而非完整词表logits,通信复杂度从O(V)降至O(d);采用锚点定长序列打包策略,避免填充带来的计算和内存开销。
我的看法:这次开源不只是技术突破,更是AI普惠的关键一步。DSpark把高并发场景下的推理效率瓶颈解决了,意味着我们日常用的AI对话系统响应会更快,企业部署大模型的成本也会降低。更难得的是,DeepSeek没有藏着掖着,直接把核心代码开源,这种开放态度比技术本身更值得点赞。
信息来源:IT之家、GitHub、Hugging Face;时间:2026年6月28日;话题:DeepSeek开源 DSpark框架 大模型推理加速 AI技术突破