如果你平时经常调用大模型 API,肯定有同一个感受:模型越来越聪明了,但生成速度还是不够快。
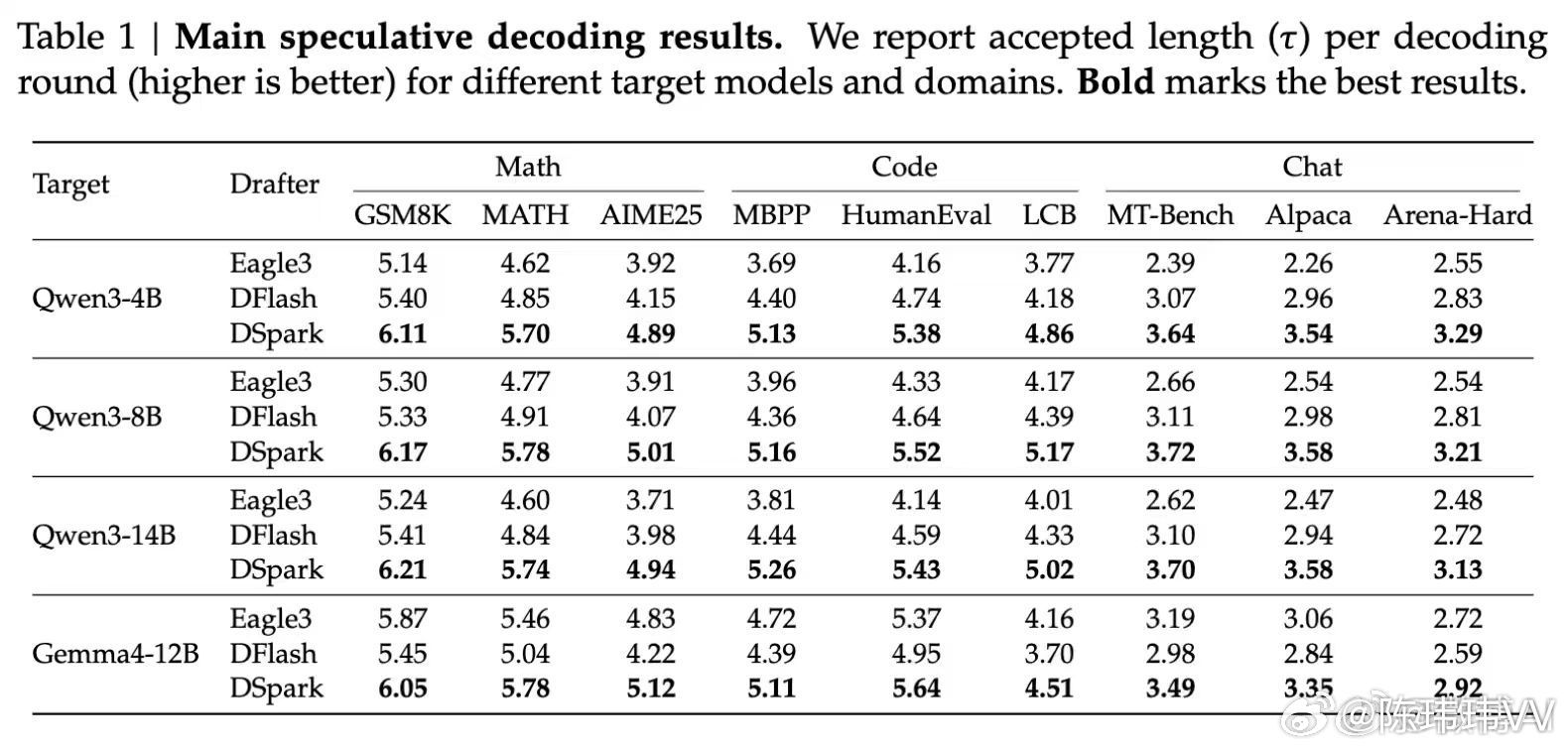
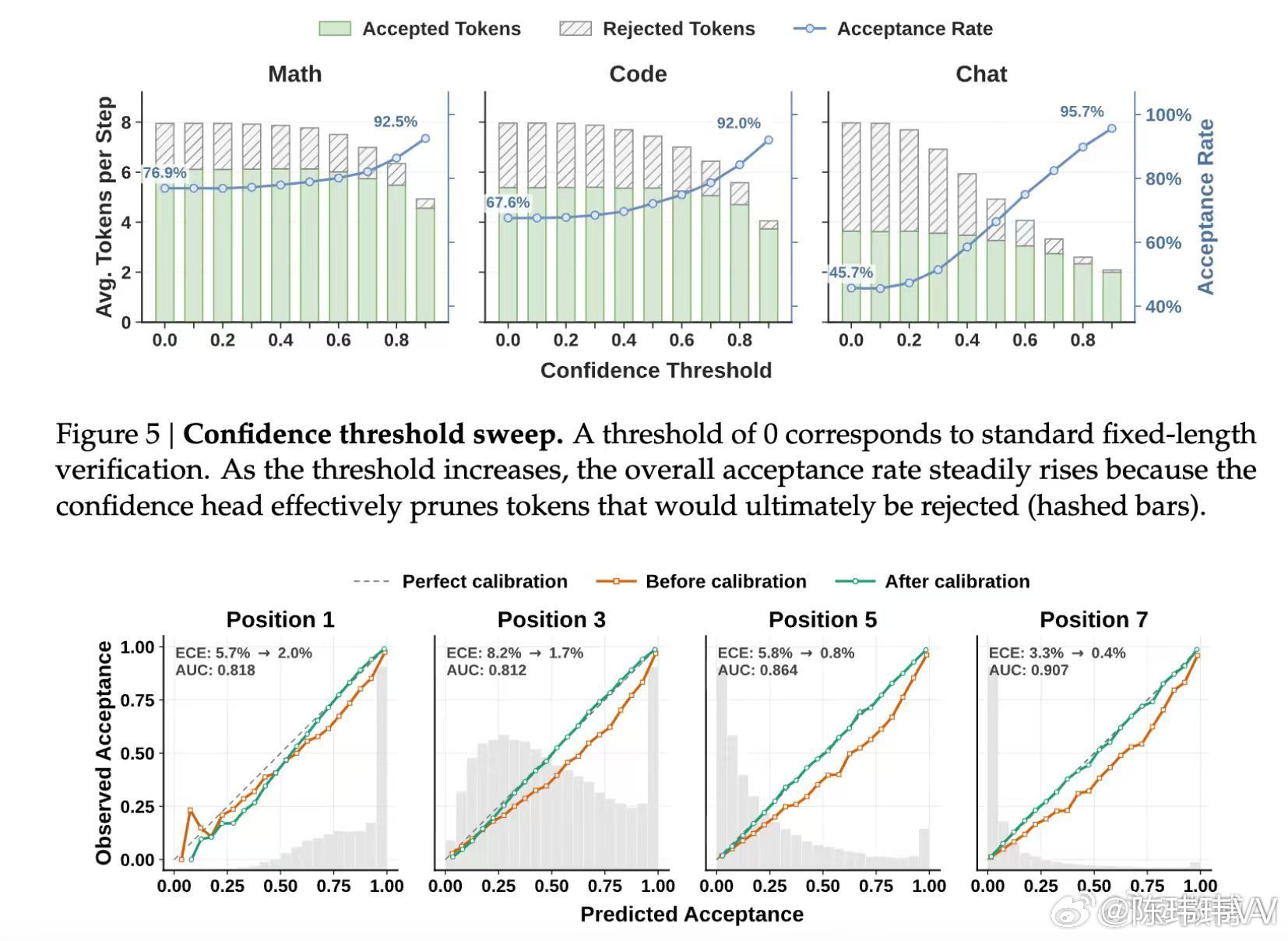
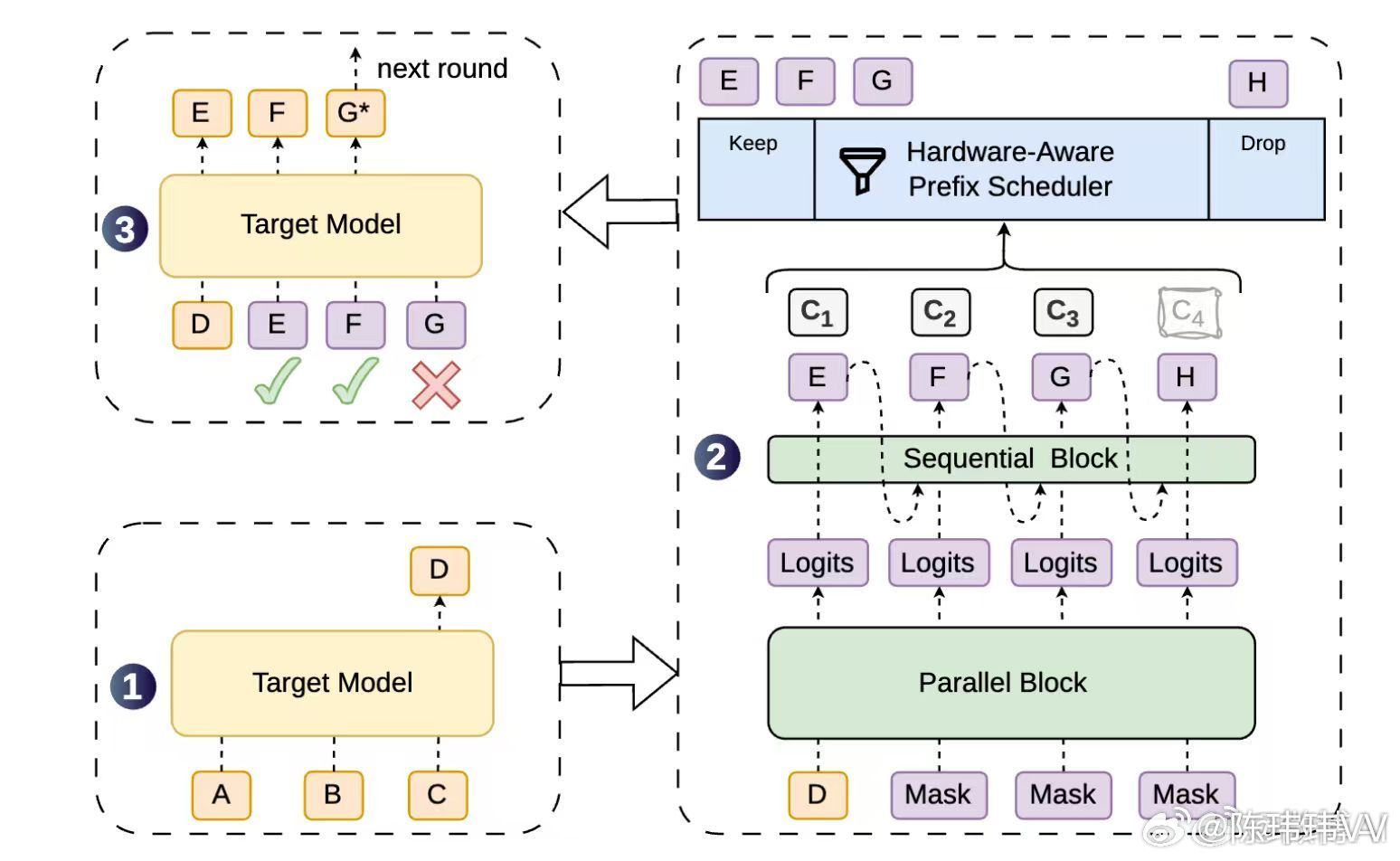
这次 DeepSeek 和北大联合发布的 DSpark,就是让大模型更快了。它采用的是推测解码(Speculative Decoding)技术。简单理解,就是先让一个小模型提前“打草稿”,再交给大模型一次性验证。如果猜得够准,大模型就不用一个 Token 一个 Token 慢慢生成,而是一次输出一整段。
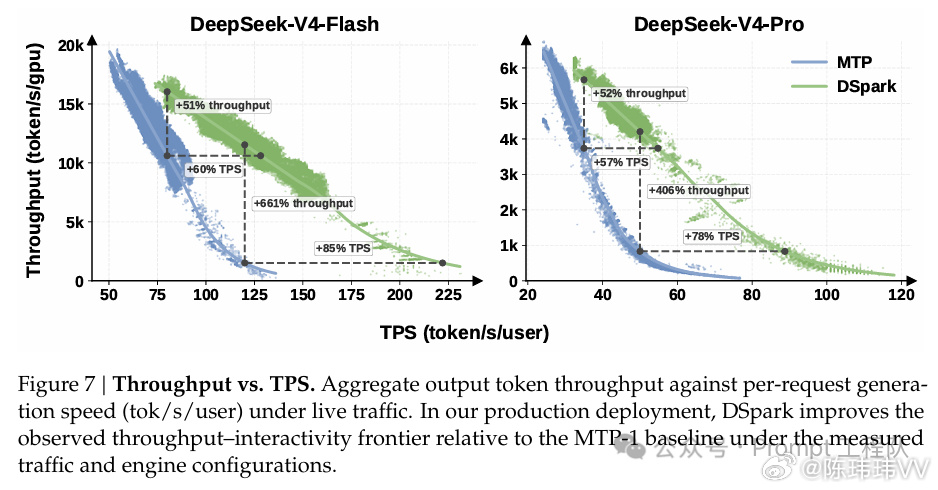
根据官方公布的数据,部署到 DeepSeek-V4 线上服务后,V4-Flash 单用户生成速度提升 60%~85%,V4-Pro 提升 57%~78%。
我觉得,大模型下一阶段竞争,比拼的可就不只是模型能力了,还有推理效率、响应速度和工程能力。毕竟,同样一句回答,如果别人2秒生成,你要等10秒,那用户体验完全不是一个级别的。deepseek发布dspark