又是华为!
华为的昇腾910C芯片,干成了一件以前大家觉得“不可能”的事,6月5日上午,深圳发布那边突然甩出一条消息,措辞挺官方,但懂行的人一眼就看出来这事儿不简单。
华为昇腾910C,1000颗,联手把那个拥有1.6万亿参数的DeepSeek-V4-Pro,从头到尾做了一次“全参数后训练”。
这不是那种小打小闹的跑个分,也不是拿现成模型测测速。这次是实打实地把一辆车抬进改装厂,拆发动机、调变速箱,把整个系统重新撸了一遍。
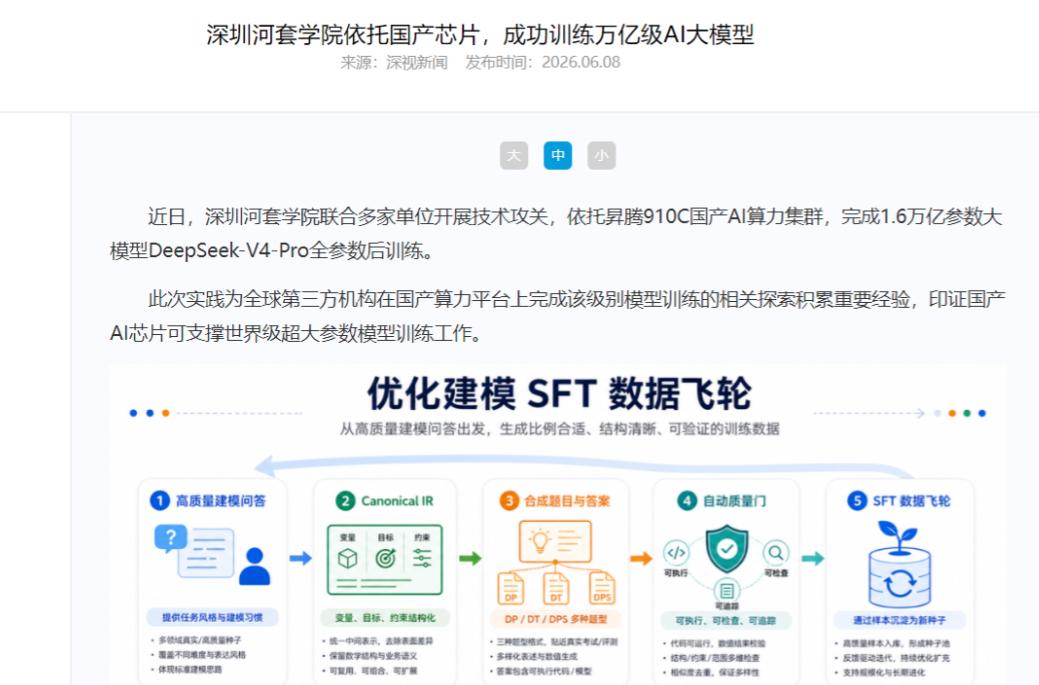
这个DeepSeek-V4-Pro可不是一般的模型,它的总参数规模高达1.6万亿,采用的是当前最主流的混合专家(MoE)架构,还搭载了CSA+HCA混合稀疏注意力、mHC连接等新机制。在同等参数量的情况下,业界公开的国产算力全参数后训练案例几乎为零,这个项目是头一回。
先得搞清楚一件事:训练和推理完全是两个概念,推理就是给已经毕业的学霸发卷子,模型参数固定不动,答一道是一道,国产芯片在这方面其实早就证明过自己了。但训练不一样,训练是从零开始教一个孩子学说话、学写字、学逻辑,需要喂进去海量数据,然后在几千甚至几万张芯片组成的集群里反复计算、调整那1.6万亿个参数,把它慢慢“教聪明”。
而“全参数后训练”更狠,它不只是调几个参数糊弄了事,而是要把模型的1.6万亿个参数从头到尾翻新一遍。做个不太严谨但很好理解的类比,这就像不是只给一辆车换几个零件,而是把整辆车抬进改装厂,拆发动机、调变速箱,把整个系统从头到尾重新撸一遍。
这次团队攻克了三大技术难题,第一是“显存拼图”,1.6万亿参数的MoE模型不可能硬塞进一张显卡里,团队精妙地把模型拆解成权重、梯度、激活、优化器四个维度,再用数据并行、张量并行、流水并行加上专家并行四管齐下,把每一个参数精确分配到千卡集群的每一张卡上,搭出了一套稳如泰山的基础底座。
第二是“负载均衡”,MoE架构的一大难题是专家负载不均,有的专家接到活干得脚不沾地,有的却在旁边干坐着,团队专门优化了调度策略,给MoE路由和专家负载上了实时监控与均衡机制,让每个专家都动起来、通信不堵车。
第三是“24小时守夜人”,全参数后训练最怕的就是跑着跑着系统突然崩溃,这次团队搭建了一套从损失曲线到梯度范数、从专家负载到显存占用的全程监控体系,能感知、能告警、能自愈。1500多步的长跑下来,没有一次报错、没有一次参数失控,这就是最硬核的成绩单。
再看具体数据,仅用1个月时间,项目就实现了DeepSeek-V4-Pro全参数续训练和SFT稳定运行,完成长稳训练1500多步,训练MFU超过30%,关键训练算子效率比初始版本提升了14%。在千卡集群上,它以27秒/步的节奏稳定奔跑,这不是实验室里的一次性演示,而是可以复制、可以工程化交付的硬实力。
深圳发布的官方报道明确指出,这次实践为全球第三方机构在国产算力平台上完成同级别模型全参数后训练的相关探索积累了重要经验,也印证了国产AI芯片可支撑世界级超大参数模型训练工作。
这次项目还有一个独特之处,产学研协同的深度捆绑,深圳河套学院把万亿级模型训练攻关当成了真正的“练兵场”,直接让学生参与进来。截至目前,已经培养了42名学生,形成了青年教师指导、博士生攻坚、工程团队支撑的协同机制。有人负责训练数据构造与样本质量分析,有人研究分布式并行策略,有人盯着监控与异常恢复,有人写技术报告。
这不是在上课,这是真刀真枪地让下一代工程师亲手操刀,从产业层面来看,长期以来全球万亿级大模型训练几乎都依赖海外高端算力产品,国内国产算力主要用在推理和小幅微调上,全参数深度训练始终是块难啃的硬骨头。
这次突破意味着国产AI算力终于从“能推理”跨到了“能训练、训得稳、训得好”的新阶段,国产AI产业链自主化水平有望大幅提升,行业应用成本也有望降下来。
好生态需要好应用来带动,DeepSeek-R1推理环节国产算力已经表现出色,这次后训练又跑通了一个关键场景。更长远来看,当国产芯片不仅能训练万亿参数大模型,还能孵化行业模型、服务实体经济,这个链条跑顺了,价值就不可估量了。