小米MiMo模型API降价
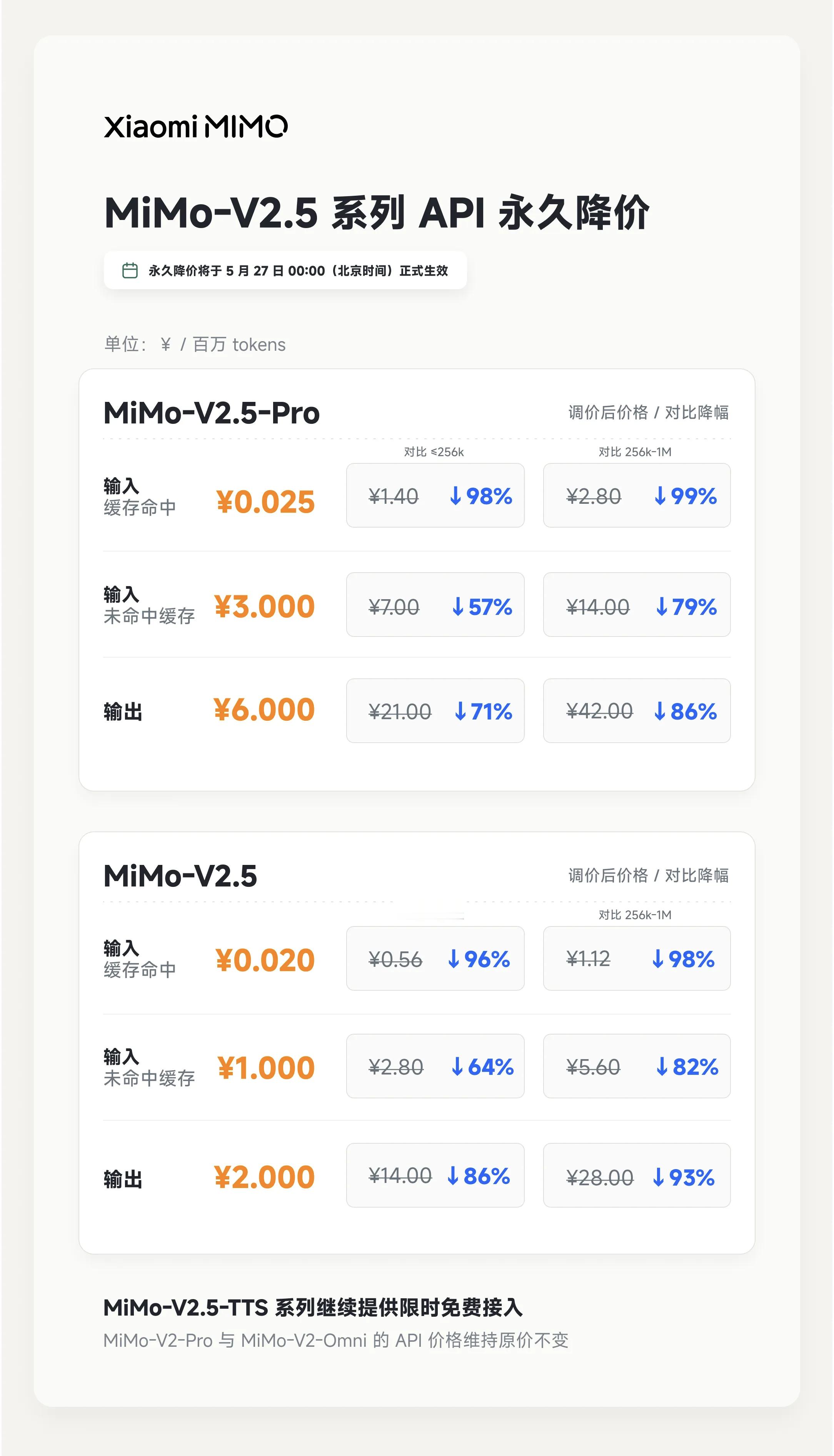
MiMo-V2.5 全系调价,官方口径最高降幅 99%,新价自北京时间 2026.05.27 00:00 生效,并且不再区分输入长度区间;V2 系列价格不变但提示即将下线。
同时,V2.5 把命中缓存与未命中缓存拆开计价:以 V2.5 为例,每百万 tokens 输入命中缓存仅 ¥0.02,未命中缓存 ¥1,输出 ¥2;Pro 版输入命中缓存 ¥0.025,未命中缓存 ¥3,输出 ¥6。
为什么能这么做?官方给出的解释抓住了大模型商业化最硬的一块成本:长上下文与重复前缀。基于 SGLang HiCache 支持 SWA(滑动窗口注意力),并把 KV Cache 在 GPU 显存、CPU 内存、SSD 多级存储里更高效地调度,搬运量据称降到优化前约 1/7,可缓存 token 数提升近 5 倍。
听起来很工程,但结论很直白:缓存命中率更高、推理效率更好,重复上下文的边际成本就能真正降下来。
把这件事放回我昨天的财报点评里看,会更清晰:小米对 MiMo 的态度是重视且务实。一方面,在成功可控的前提下坚决跟进 DeepSeek 的定价,把调用量做起来;
另一方面,不靠单纯烧钱补贴,而是试图用推理优化把成本曲线压平,让 Token Plan 更清晰、价格更可持续。
从技术能力的精进到投入力度的坚决,小米 AI 这条线正在全方位发力。短期资本市场可能对价格战、利润表体现、投入回报周期仍有分歧,但当 AI 深入改造人车家全生态,模型能力与成本曲线最终会落到“体验与渗透率”上。长期看,这会成为小米新一轮估值的重要支撑。小米科技