[LG]《LLMs as Noisy Channels: A Shannon Perspective on Model Capacity and Scaling Laws》X Ouyang, D Liu, Y Cai, J Liu… [ByteDance Seed] (2026)
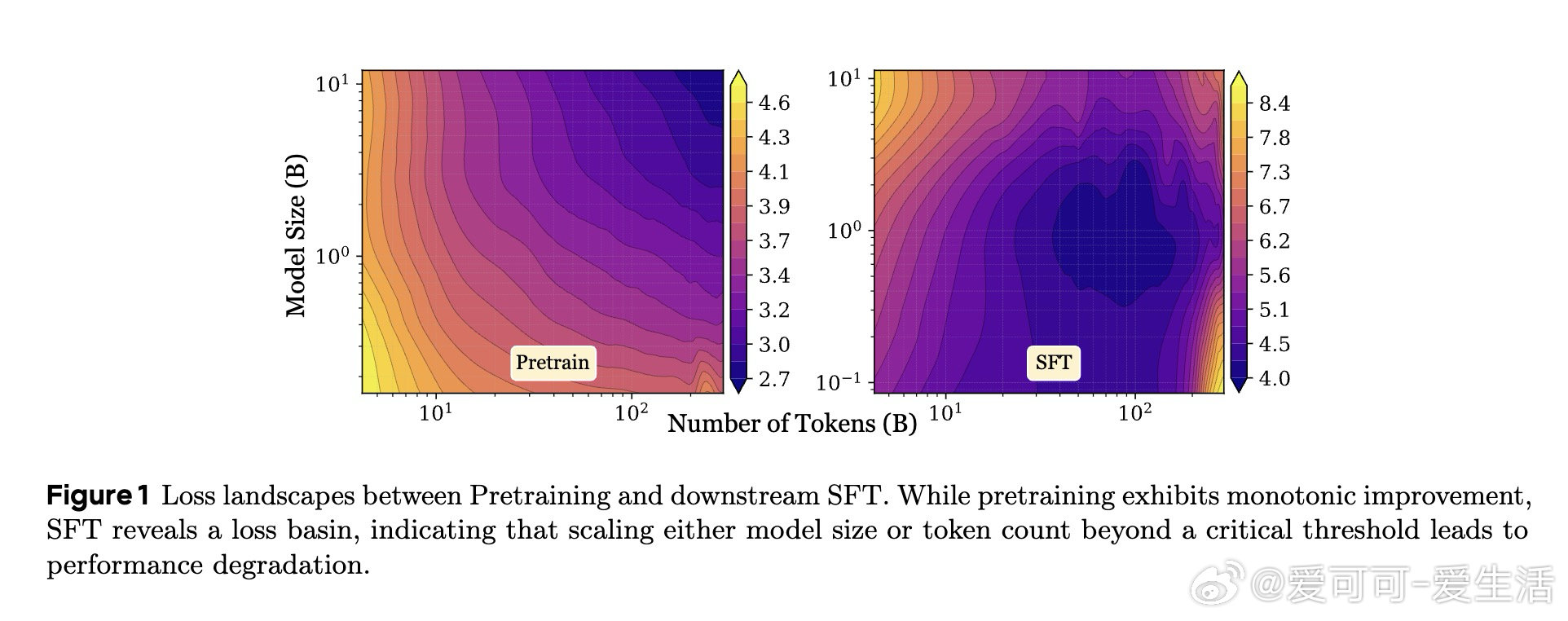
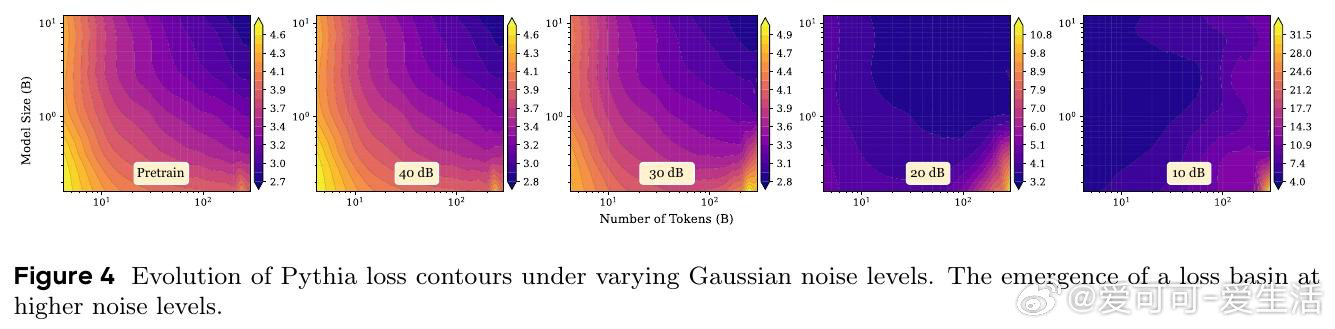
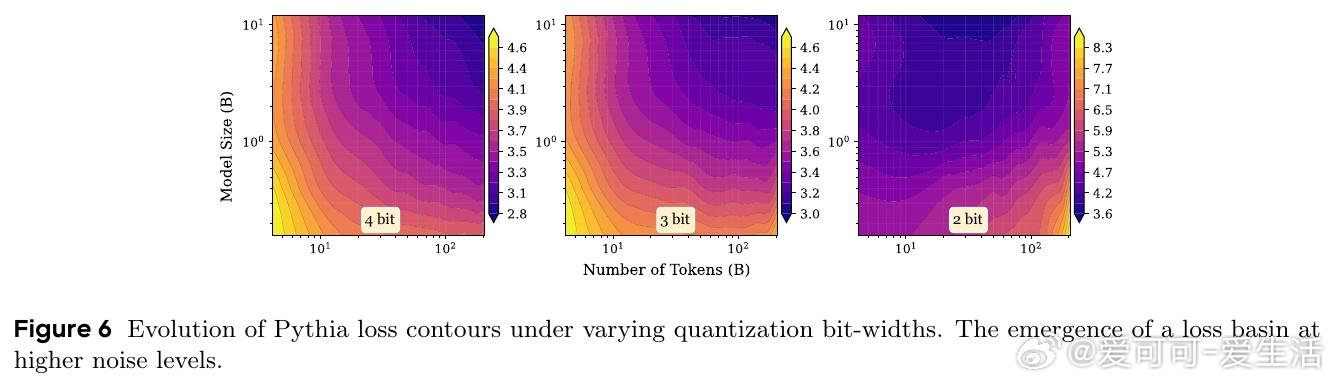
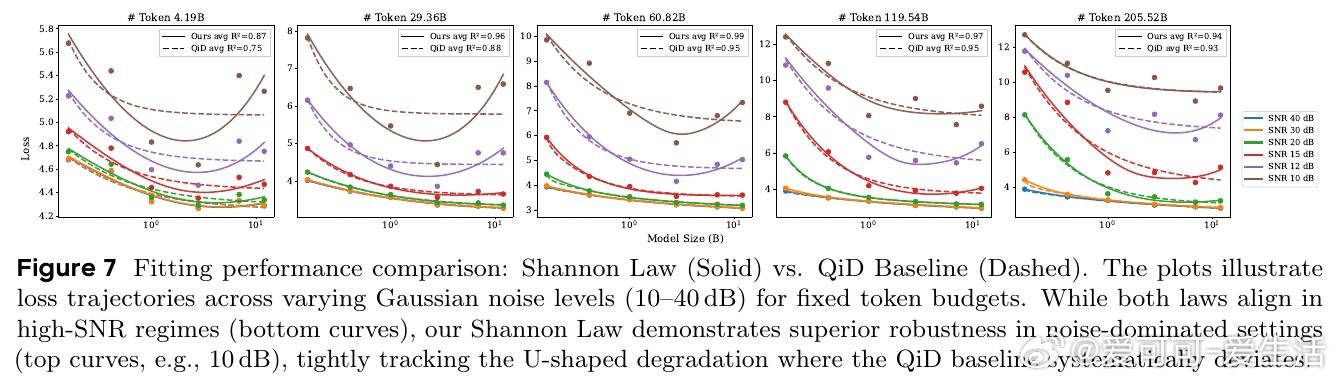
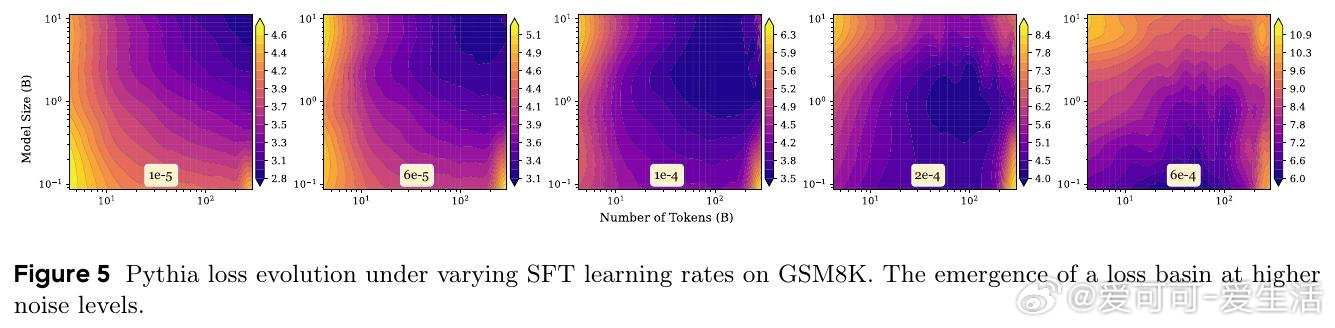
在LLM缩放领域,“越大越好”遇到反例:过训、量化会让性能回落。过去幂律只看参数和数据收益,忽略噪声会随规模一同放大。
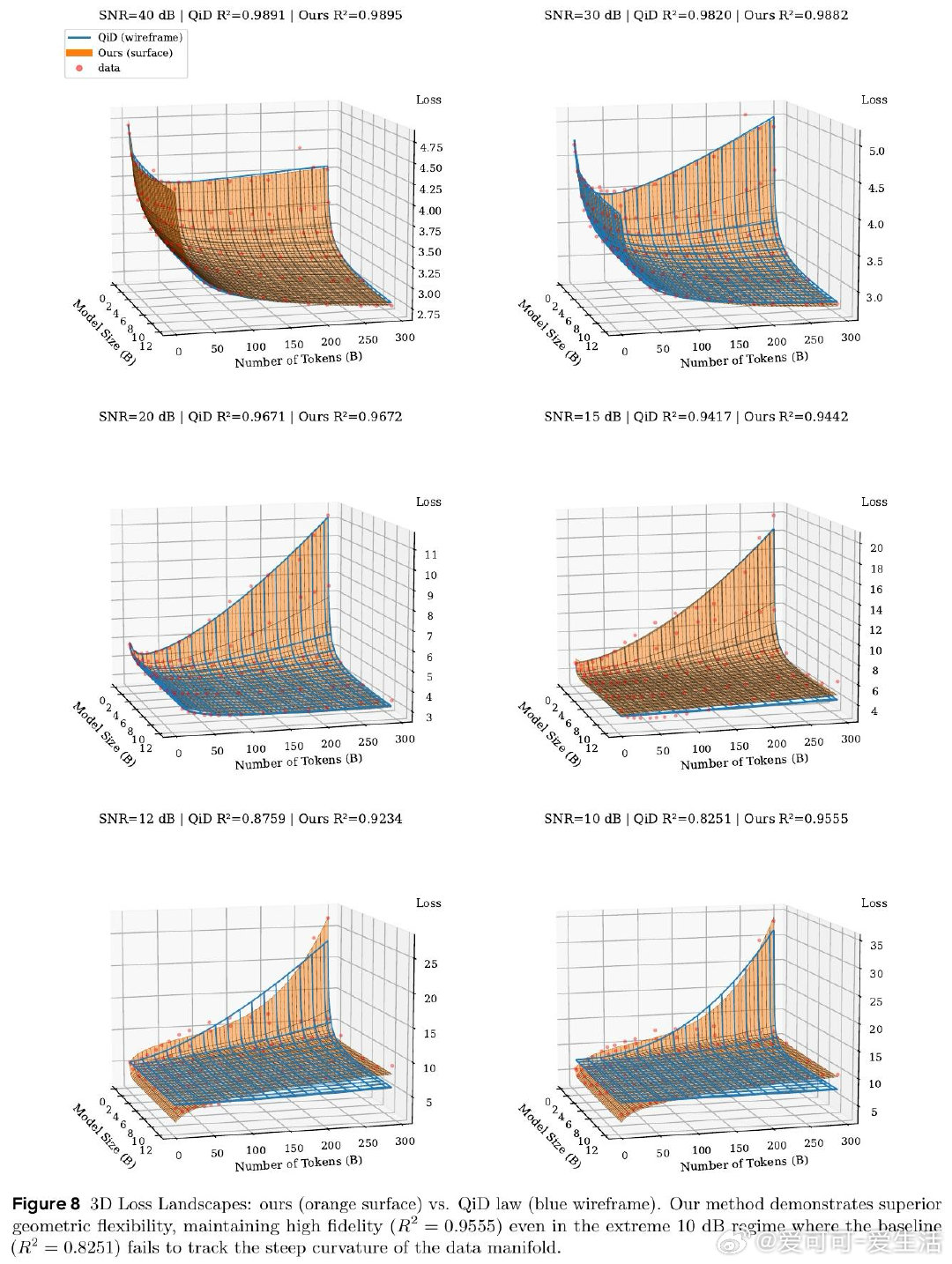
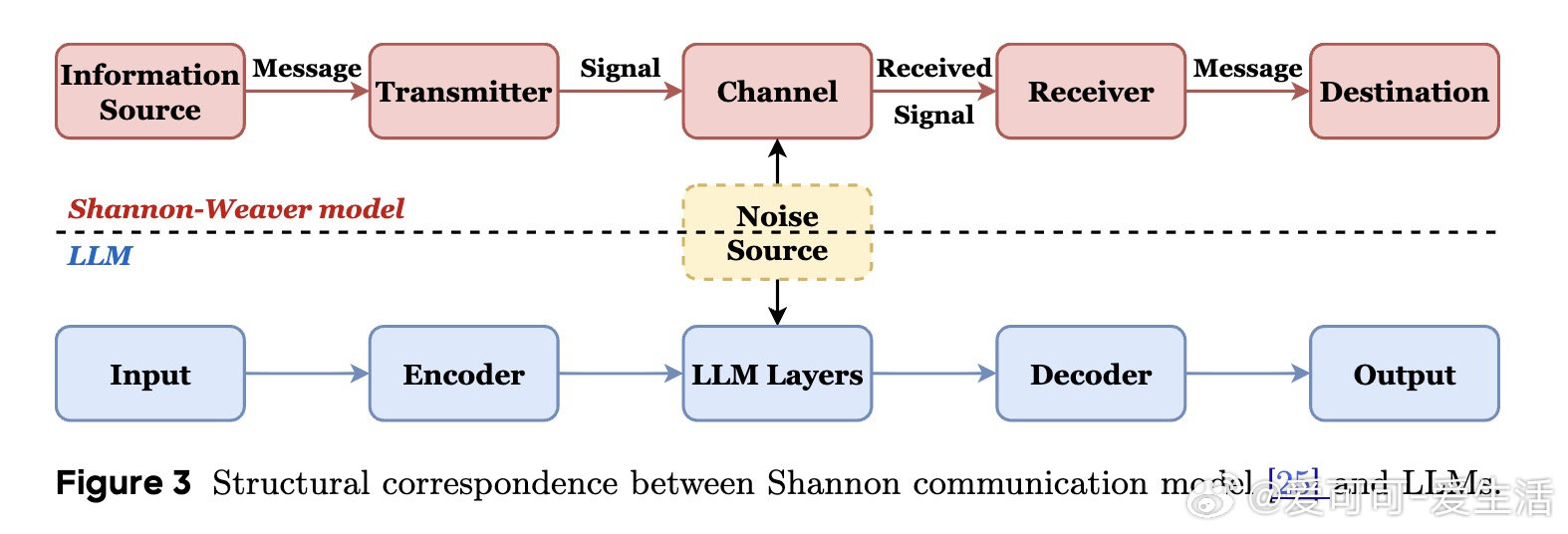
本文的核心洞见是:把LLM重新看作带噪信道。由此,用参数表征带宽、数据表征信号、训练与扰动表征噪声,解释U形损失盆地。
这项工作留下的遗产是把缩放边界写进同一条容量公式。它打开的新门是按信噪比规划训练;尚未跨过的门槛是更多架构与真实训练噪声验证。
arxiv.org/abs/2605.23901 机器学习 人工智能 论文 AI创造营