GTC秀CPO、秀LPU,曙光scaleFabric直接甩856K QP
GTC 2026上,英伟达展示了解耦推理新架构:Rubin GPU负责prefill,Groq LPU负责token生成,分工明确。黄仁勋说这样能把推理吞吐量提升35倍。
但解耦的前提是什么?网络必须足够强,GPU和LPU之间要像连体婴儿一样协同,任何一点延迟都能让35倍变成3.5倍。英伟达有自己的InfiniBand兜底,那国产拿什么对标?
过去大家只能靠RoCE——在以太网上跑RDMA,便宜但坑多。PFC风暴、ECMP哈希不均、DCQCN失效,Meta在Llama 3万卡集群里被这些问题折磨得欲仙欲死。
现在,中科曙光直接甩出scaleFabric,给了一个更硬的答案。
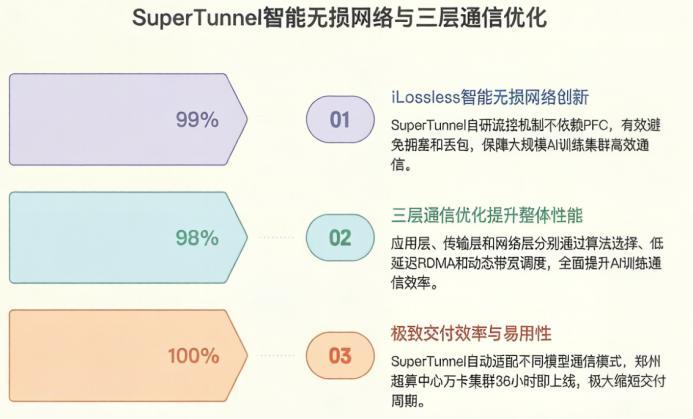
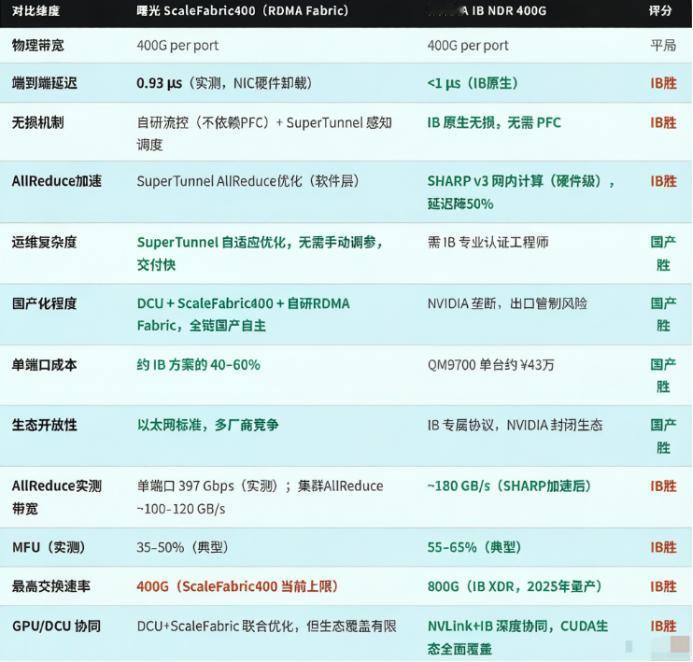
单卡QP支持856K,是英伟达CX-7的6.7倍。 QP是什么?队列对,RDMA并发通信的核心指标。856K意味着万卡集群里每张卡能跟所有卡同时聊天,不排队、不打架。
再看无损网络:IB靠PFC容易引发风暴,曙光搞iLossless智能流控不依赖PFC,动态避免拥塞。你搞解耦,我搞并发;你靠硬件,我靠协议。
英伟达SHARP v3硬件AllReduce确实强,但曙光的SuperTunnel软件优化+自研协议,把并发提上去、成本打下来。解耦推理再牛,网络跟不上也是白给。
总结一下
RoCE的定位很清晰:用更便宜的成本,在中小规模集群里跑出接近IB的效果。它不完美,配置复杂,大规模下问题多,但胜在开放、灵活、省钱。
而中科曙光scaleFabric的路线其实更接近IB——原生RDMA架构,自研协议,硬件级流控,而不是在以太网上打补丁,直接做自己的IB。
GTC2026 中科曙光 scaleFabric RoCE